

Introduction
Biostatistics has long been the backbone of biomedical research, public health, clinical trials, and epidemiology. Traditionally, statistical methods such as regression analysis, hypothesis testing, and experimental design have been used to analyze biological and medical data. However, the rapid growth of big data, high-throughput technologies, and electronic health records (EHRs) has pushed traditional biostatistical methods to their limits.
This is where Machine Learning (ML) steps in.
Machine Learning, a subset of artificial intelligence, enables computers to learn patterns from data without being explicitly programmed. When combined with biostatistics, ML offers powerful tools to analyze complex, high-dimensional biological data, improve predictive accuracy, and uncover hidden relationships that classical methods may miss.
This article explores Machine Learning in biostatistics, its core techniques, applications, advantages, limitations, and future directions—written specifically for students, researchers, and data-driven health professionals.

What Is Machine Learning in Biostatistics?
Machine Learning in biostatistics refers to the application of computational algorithms that automatically learn from biological, clinical, or health-related data to make predictions, classifications, or discoveries.
While traditional biostatistics focuses on inference, parameter estimation, and hypothesis testing, machine learning emphasizes:
- Prediction accuracy
- Pattern recognition
- Automation
- Scalability to large datasets
In practice, modern biomedical research increasingly blends statistical rigor with machine learning flexibility, creating a hybrid analytical approach.
Why Machine Learning Is Important in Biostatistics
Several factors have accelerated the adoption of ML in biostatistics:
- Explosion of genomic, proteomic, and metabolomic data
- Increasing availability of real-world clinical data
- Need for personalized and precision medicine
- Complex nonlinear relationships in biological systems
- Limitations of assumptions in classical models
Machine learning methods can handle missing data, nonlinearity, high dimensionality, and complex interactions more effectively than many traditional statistical tools.
Types of Machine Learning Used in Biostatistics
Machine learning algorithms used in biostatistics can be broadly classified into four categories.
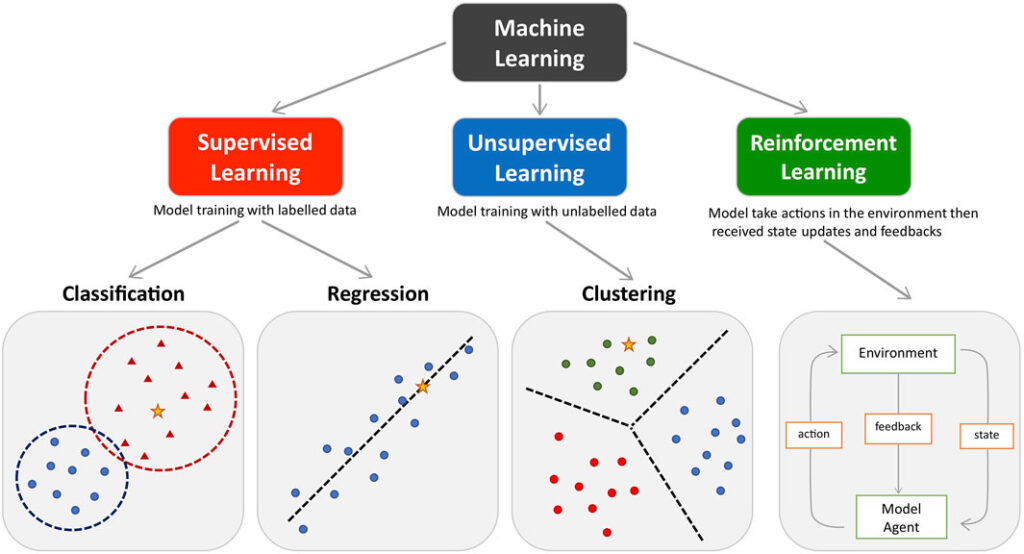
1. Supervised Learning
Supervised learning uses labeled data, where the outcome variable is known.
Common algorithms:
- Linear and Logistic Regression
- Decision Trees
- Random Forest
- Support Vector Machines (SVM)
- k-Nearest Neighbors (k-NN)
- Neural Networks
Biostatistical applications:
- Disease risk prediction
- Patient survival analysis
- Diagnostic classification
- Treatment outcome prediction
2. Unsupervised Learning
Unsupervised learning identifies hidden patterns in unlabeled data.
Common algorithms:
- K-means clustering
- Hierarchical clustering
- Principal Component Analysis (PCA)
- t-SNE
Biostatistical applications:
- Patient subgroup identification
- Gene expression clustering
- Biomarker discovery
- Exploratory data analysis
3. Semi-Supervised Learning
This approach combines labeled and unlabeled data, useful when labeling is expensive or time-consuming.
Applications:
- Medical imaging analysis
- Rare disease research
- Genomic annotation
4. Reinforcement Learning
Reinforcement learning optimizes decisions through trial-and-error interactions.
Applications:
- Adaptive treatment strategies
- Dynamic dosing regimens
- Clinical decision support systems
Traditional Biostatistics vs Machine Learning
| Feature | Traditional Biostatistics | Machine Learning |
|---|---|---|
| Primary goal | Inference and explanation | Prediction and pattern discovery |
| Model assumptions | Strong (normality, linearity) | Minimal or none |
| Data size | Small to moderate | Large and high-dimensional |
| Interpretability | High | Often lower |
| Automation | Limited | High |
| Handling complexity | Moderate | Excellent |
Key Applications of Machine Learning in Biostatistics
1. Clinical Research and Trials
ML improves:
- Patient recruitment
- Outcome prediction
- Adverse event detection
- Trial optimization
Predictive models help identify high-risk patients and forecast treatment responses.
2. Genomics and Bioinformatics
High-throughput sequencing generates massive datasets. ML is used for:
- Gene expression classification
- Variant calling
- Disease-gene association studies
- Protein structure prediction
3. Epidemiology and Public Health
ML models assist in:
- Disease outbreak prediction
- Risk factor identification
- Surveillance systems
- Population health modeling
These methods support faster and more accurate public health responses.
4. Medical Imaging and Diagnostics
Deep learning techniques analyze:
- X-rays
- MRI scans
- CT images
- Histopathological slides
ML often achieves diagnostic performance comparable to expert clinicians.
5. Personalized and Precision Medicine
ML enables:
- Patient stratification
- Treatment personalization
- Drug response prediction
- Prognostic modeling
This aligns perfectly with modern precision healthcare goals.
Advantages of Machine Learning in Biostatistics
- Handles complex, nonlinear data
- Scales to very large datasets
- Improves predictive accuracy
- Reduces manual model specification
- Integrates multi-source biomedical data
- Supports real-time decision making
Challenges and Limitations
Despite its power, ML in biostatistics faces important challenges:
- Interpretability: Many models act as “black boxes”
- Overfitting: Risk with small sample sizes
- Data quality issues: Missing, biased, or noisy data
- Ethical concerns: Privacy, fairness, transparency
- Reproducibility: Model validation is essential
Biostatistical expertise remains crucial to ensure valid and ethical results.
Best Practices for Using ML in Biostatistics
- Combine ML with classical statistical reasoning
- Use cross-validation and external validation
- Prioritize interpretability when possible
- Perform sensitivity and robustness checks
- Document data preprocessing and modeling steps
Future of Machine Learning in Biostatistics
The future points toward:
- Explainable AI models
- Integration of causal inference with ML
- Real-time clinical decision support
- Federated learning for privacy-preserving analysis
- Greater collaboration between statisticians, clinicians, and data scientists
Machine learning will not replace biostatistics—it will expand its power and scope.
Conclusion
Machine Learning has become an indispensable tool in modern biostatistics. By enabling advanced pattern recognition, prediction, and automation, ML enhances our ability to analyze complex biomedical data and improve health outcomes.
However, successful application requires careful study design, statistical understanding, ethical awareness, and rigorous validation. When combined thoughtfully with classical biostatistical principles, machine learning opens new horizons in biomedical research, public health, and personalized medicine.
As data continues to grow in size and complexity, the synergy between biostatistics and machine learning will define the future of data-driven healthcare.